

在检索增强生成(RAG)系统中,稠密检索器(Dense Retriever)认真从海量文档库中快速找出与查询语义最关联的段落,是通盘系统的中枢基础组件。
但是,考试一个高质地的稠密检索器并浮松易。对比学习(Contrastive Learning)永恒以来是这一范围的主流范式,但存在几个根人道局限:
严重依赖东说念主工标注数据:需要悉心构造查询 - 文档正负样本对,在代码、法律等专科范围标注资本极高;
难负样本的窘境:马上负样本信号太弱,难负样本挖掘又引入畸形复杂性;
与话语模子预考试目的割裂:对比亏空与主流大模子的预考试范式(下一词预测)自然不兼容,难以充分复用预考试学问。
这些问题在专科范围和推理密集型检索场景下尤为杰出。能否找到一条更当然、更兼并的检索器考试旅途?来自德国达姆施塔特工业大学(TU Darmstadt)的蔡丰宇偏执来自华盛顿大学、卡内基梅隆大学、微软和腾讯 AI 施行室的联结者给出了一个优雅的谜底 - Revela:Dense Retriever Learning via Language Modeling,并凭借这一回报斩获 ICLR 2026 Oral (约 1.1% 选取率) 和 FrontierIR @ AAAI 2026 最好论文奖。

中枢想路:让检索「像话语模子一样学习」
Revela 的中枢瞻念察在于:将稠密检索器的考试目的兼并到话语建模框架之下。
话语模子(LM)通过 "预测下一个 token" 来建模 token 之间的依赖干系。Revela 将这一想路类比到检索:淌若说 LM 建模的是 token 之间的依赖,那么检索器建模的等于文本块(chunk)之间的依赖。
具体而言,Revela 引入了一种批内注想法机制(In-batch Attention):在话语建模时,一个序列的下一词预测不仅要求于自身上文,还通过检索器预备的相似度权重,动态地参考批次中其他关联文档。如图 1 中,红色文本块在预测下一词时 "参考" 了语义周边的紫色文本块,这也曾过反过来驱动检索器提高两者之间的相似度分数。检索器的相似度分数就此平直镶嵌话语建模的优化目的,终了检索器与话语模子的连合端到端考试,无需任何东说念主工标注的查询 - 文档对。
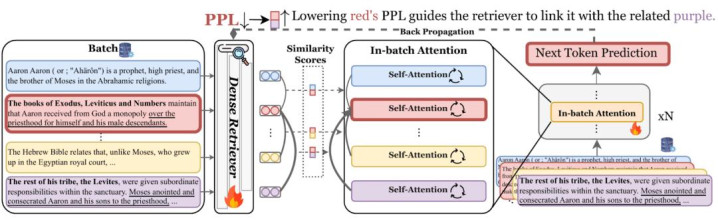
图 1:Revela 考试框架。检索器相似度分数动作批内注想法权重,与话语模子连合端到端考试。红、紫序列中高亮片断展示了检索器怎样学会关联语义周边的文本块。
这一想象带来了三个要道上风:
考试目的与预考试高度一致:话语建模恰是大模子预考试所禁受的目的,Revela 与之自然对都,能充分激活预考试模子中已有的语义兼并智力。
全都自监督,无需标注:原始文本自身的迂回文干系即组成考试信号,大幅镌汰对东说念主工标注的依赖,使要领在数据稀缺的专科范围具备自然上风。
可扩张性强:施行标明,跟着检索器范围(从 135M 到 3B)、话语模子范围和批大小的增大,性能捏续沉稳擢升,展现出细致的 Scaling 特质。
要领架构
Revela 的举座架构由两部分组成:认真编码文本,预备相似度的检索器,以及提供话语建模考试信号的话语模子,dafa大发手机版app二者在考试经过中连合优化。
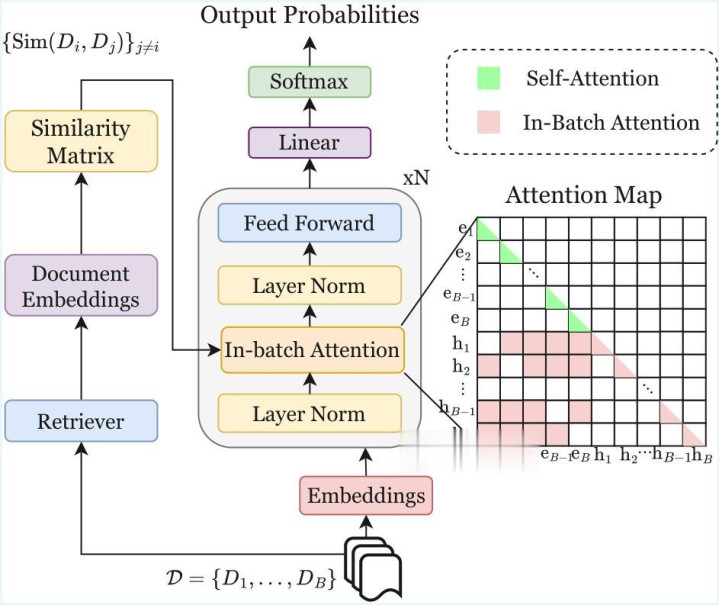
图 2:Revela 的 Transformer Block 架构。
中枢改造汇集在 LM 的 Transformer Block 里面(图 2)。每一层同期初始两条并行的注想法旅途:轨范自注想法处理单条序列里面的迂回文依赖,输出 ei;批内注想法则在此基础上引入跨文档维度:先对序列自身作念自注想法获得 si,再以检索器输出的相似度分数为权重,对批次内其他文档的自注想法输出 ej 作念交叉注想法并加权团员获得 bi,最终输出 hi = si + bi。其中,检索器将批次内统共文档编码为向量,通过两两余弦相似度并经 softmax 归一化,获得文档间的相似度权重矩阵,平直动作批内注想法的团员权重。
值得凝视的是,跨文档注想法的 Key 和 Value 均来自其他文档的 ej,而非 hj,这一想象使批内注想法或者使用只含有序列里面信息的自注想法。两路旅途对应图 2 注想法图中左上与右下两个区域,最终输出相加后送入前馈层,共同驱动下一词预测目的。这一想象使检索器的相似度分数平直参与 LM 的反向传播,Dafabet检索器由此得以被端到端优化。
在考试数据构建上,Revela 将文档切分为 chunk 并分批,确保每个 batch 内包含语义关联的片断,使话语建模信号自然对应挑升想的跨文本依赖。考试数据方面,通用检索使用约 34 万篇维基百科文档,代码检索使用 StackOverflow 帖子、时刻教程和库文档,均无需任何东说念主工标注的查询-文档对。
施行效果:无标注数据,超越贸易 API
Revela 在三大巨擘基准上进行了系统评估,远隔遮蔽代码检索(CoIR)、推理密集型检索(BRIGHT)和通用信息检索(BEIR)三个维度。
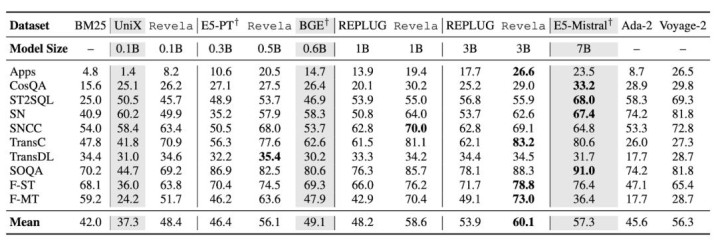
表 1:CoIR 代码检索基准上各模子的检索性能(nDCG@10,%)。
代码检索(CoIR): Revela-3B 在 10 项任务平均 nDCG@10 达到 60.1,在无需任何查询 - 文档标注对的前提下,超越了使用海量标注数据考试的 7B 参数有监督模子 E5-Mistral-7b-Instruct(57.3)以及 OpenAI Ada-002(45.6)、Voyage-Code-002(56.3)两个贸易 API。在 0.5B 参数范围下,Revela 即超越了相通遮蔽代码语料、用 2.7 亿标注对考试的 E5-PT,越过约 10 个百分点。
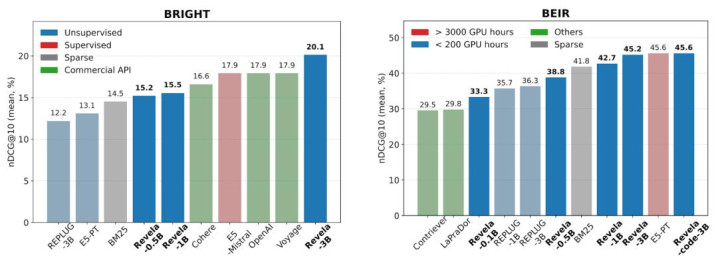
图 3:BRIGHT(左)与 BEIR(右)基准上的检索性能对比(nDCG@10,%)。
推理密集检索(BRIGHT): Revela-3B 平均 nDCG@10 达到 20.1,仅凭维基百科文本考试,便超越了 E5-Mistral-7b-Instruct(17.9)以及 text-embedding-3-large(OpenAI,17.9)、voyage-large-2-instruct(Voyage,17.9)、cohere-embed-english-v3.0(Cohere,16.6)等主流贸易 API,充分体现了话语建模目的对深层语义推明智力的激活效果。
通用检索(BEIR): Revela-3B 与弱监督基线 E5-PT 捏平(均为 45.6),但所用考试数据约为其 1/1000,使用预备资源仅为其 1/10,极大镌汰了考试资本。
道理与预测
Revela 将稠密检索器的考试与话语建模范式兼并,灵通了多个值得探索的方针:
动态索引构建:Revela 当今通过文档分块来保证 batch 内的语义关联性,更生机的作念法是用模子的及时暗示对 chunk 动态分组,但这意味着需要在考试经过中捏续更新索引,预备资本是亟待贬责的挑战。模子与数据的进一步扩张:施行已考据 Revela 在模子范围和 batch 大小上具备细致的 Scaling 特质,扩大考试语料遮蔽范围、引入更高效的注想法机制,有望带来进一步的性能擢升。反哺话语模子考试:Revela 当今将 LM 视为援助的考试信号开端,但检索器所学到的文本间语义关联,相通不错反过来用于诱导 LM 的 batch 构建,探索对话语模子自己的改善后劲。
该效果已以 Oral 方法发表于顶级 AI 会议 ICLR 2026。本届 ICLR 共收到近两万篇投稿,Oral 仅 两百余篇,选取率约 1.1%,是对 Revela 在自监督检索学习范围改造价值的高度招供。
作家先容
蔡丰宇,德国达姆施塔特工业大学(TU Darmstadt)四年齿博士dafa大发手机版app,师从 ACL fellow,前 ACL 主席 Iryna Gurevych 教养及 Heinz Koeppl 教养。他洽商方针涵盖稠密检索、RAG 及 AI for science,在 ICLR,ACL, EMNLP,CVPR 等会议上发表论文十余篇。本硕远隔毕业于香港科技大学(HKUST)与洛桑联邦理工学院(EPFL)。
IM体育官方网站首页 备案号:
备案号: